
Neste artigo você verá:
– Por que não executar migrations dentro da aplicação
– Como usar o ArgoCD com PreSync hooks
– Como integrar Liquibase via Kubernetes Job
– Boas práticas com segurança e armazenamento
– Considerações sobre rollback e maturidade técnica
Uma das preocupações ao lidar com aplicações é a evolução do schema do banco de dados, seja em estrutura de tabelas, índices e demais objetos quanto ao próprio crescimento do banco em si. Ferramentas como Liquibase e Flyway são bastante comuns em muitos projetos, auxiliando no versionamento dos scripts, auditoria e diversos outros benefícios.
Em projetos menores ou em provas de conceito talvez faça sentido adicionar essa responsabilidade à aplicação em si: ou seja, ao iniciar o serviço as migrations (ou scripts) são executadas em seu startup, e em caso de sucesso a aplicação estará pronta para atender o usuário.
Porém em projetos maiores ou de maiores exigências talvez essa não seja a melhor abordagem. Com o passar do tempo mais e mais scripts de migration são acumulados com o tempo e isso impacta diretamente na aplicação, pois precisamos garantir que todas as migrations serão executadas e que o que está definido no script não tenha sido alterado com o que está aplicado de fato no banco de dados.
Todas essas coisas adicionam mais carga à aplicação que absorveu essa responsabilidade, uma vez que a única preocupação deveria apenas subir uma nova versão. O que acontece em um pico de utilização em seu sistema onde precisamos provisionar mais réplicas? O ideal é que o provisionamento seja o mais agressivo possível. Ao ter esse “pedágio” da ferramenta de migrations podemos impactar diretamente na experiência de nossos usuários. Outro ponto importante é a questão da concorrência: como garantir que não teremos race condition em múltiplos pods executando migrations ao mesmo tempo? Podemos gerar lock e travar todo o processo de rollout.
Solução proposta
Não existem soluções mágicas e que não tenham seus próprios desafios, porém a proposta de solução não é exatamente uma novidade, [1]citada inclusive em um post do próprio liquibase. O que vou apresentar aqui é uma evolução dessa ideia e que funciona (sim, rodando em produção em um case real!).
ArgoCD hooks
Se você não está utilizando uma estratégia de GitOps recomendo que considere incluir isso em sua arquitetura. Neste case será apresentado o ArgoCD, que possui um mecanismo chamado de Resource Hooks. A ideia é que você defina um job/script que possa ser executado em diferentes fases do processo de rollout de uma nova versão. Você escolhe: quer executar algo antes, como um pre-check? Utilize um PreSync. Quer customizar o processo de rollout com regras mais complexas? Utilize o Sync. Checagens posteriores ao rollout? PostSync é seu amigo. Ou seja, perceba que temos grandes oportunidades para resolver nosso problema de migrations.
Sabemos que precisamos executar nossos scripts antes da versão ser efetivamente deployada, então vamos estudar o PreSync e ver na prática a utilização deste componente!
PreSync hook
Como o ArgoCD é totalmente declarativo, você pode definir o seu PreSync como um job normal do Kubernetes, sim, aquele mesmo que você já utiliza em seu dia a dia. A única diferença? Você precisa deixar o argo ciente de que este job é um PreSync, adicionando a seguinte annotation:
argocd.argoproj.io/hook: PreSync
Sim, é exatamente isso. Com uma linha de código você já tem seu PreSync quase pronto. Vamos agora para a parte mais legal.
Como integro isso com o Liquibase?
Já sabemos que vamos utilizar o Liquibase, então a primeira coisa que precisamos fazer é ter uma imagem docker disponível desta ferramenta para utilizar. Vá até o docker hub e localize a sua versão preferida.
Conforme a documentação oficial da imagem do Liquibase, podemos executar os comandos da seguinte forma:
docker run --env LIQUIBASE_COMMAND_USERNAME \ --env LIQUIBASE_COMMAND_PASSWORD \ --env LIQUIBASE_COMMAND_URL \ --env LIQUIBASE_COMMAND_CHANGELOG_FILE \ --rm -v /path/to/changelog:/liquibase/changelog liquibase/liquibase \ update
Vamos transferir isso para nosso Job e escrever o manifesto Kubernetes:
apiVersion: batch/v1
kind: Job
metadata:
name: meu-pre-sync
annotations:
argocd.argoproj.io/hook: PreSync
spec:
backoffLimit: 0
template:
spec:
containers:
- name: liquibase
image: my-liquibase:latest
resources:
requests:
cpu: "10m"
memory: "200Mi"
limits:
memory: "200Mi"
env:
- name: LIQUIBASE_COMMAND_USERNAME
valueFrom:
secretKeyRef:
name: db-credentials
key: username
- name: LIQUIBASE_COMMAND_PASSWORD
valueFrom:
secretKeyRef:
name: db-credentials
key: password
- name: LIQUIBASE_COMMAND_URL
value: jdbc:postgresql://meu-banco:5432/minha-base
- name: LIQUIBASE_CHANGELOG_FILE
value: /liquibase/changelog/db.changelog-master.xml
restartPolicy: Never
Neste exemplo estamos recuperando os valores de usuário e senha do banco de dados em objetos do tipo Secret do Kubernetes para facilitar o entendimento, entretanto não é a estratégia mais recomendada, pois Secrets são valores encodados em base64 sendo facilmente recuperados. O ideal é utilizar uma abordagem como por exemplo o Hashicorp Vault ou uma outra solução de cofre de senhas.
Na variável LIQUIBASE_CHANGELOG_FILE estamos informando o diretório que vão conter os changelogs… mas parece estar faltando algo aqui: em nenhum momento definimos nada disso, ou seja, esse arquivo db.changelog-master.xml sequer existe dentro da imagem de nosso container. De onde está vindo isso?
Imagem levemente customizada
E aqui entra a peça final de nosso quebra cabeças. Podemos criar uma imagem customizada do liquibase apenas para incluirmos esses scripts de migration dentro da imagem. Claro, há desvantagens nessa abordagem (no final vou propor uma solução mais elegante): caso alguém consiga explorar essa imagem vai conseguir ver a estrutura do seu banco de dados explorando os scripts que foram empacotados na imagem docker:
FROM liquibase/liquibase:4.31.1-alpine WORKDIR /liquibase/changelog COPY ./changelog/ /liquibase/changelog/
Supondo que na sua máquina (ou no seu CI/CD) você tenha a seguinte estrutura de diretórios:
|-Dockerfile |____changelog/ |- migration1.xml |- migration2.xml |- migration1.xml |- db.changelog-master.xml
E então: docker build -t my-liquibase .
Evitando adicionar os scripts na imagem Docker
A evolução dessa abordagem é uma estratégia envolvendo a montagem de um volume diretamente no seu Pod. Falando de AWS podemos utilizar o [2]Mountpoint for Amazon S3 CSI driver, que vai permitir criarmos um PersistentVolume mapeando para um bucket S3 e assim termos o cenário ideal:
...
volumeMounts:
- name: meu-storage
mountPath: /liquibase/changelog/
...
volumes:
- name: meu-storage
persistentVolumeClaim:
claimName: bucket-s3-pvcDesta forma não temos mais que nos preocupar com a questão de segurança em termos nossos scripts dentro da própria imagem Docker, deixando a solução mais elegante, além de termos uma imagem significativamente menor.
Juntando as peças
Ok… toda essa complicação, mas qual é o retorno desse investimento?
Todas as vezes que ArgoCD iniciar o rollout de uma nova versão vamos ver que ele iniciará a etapa de PreSync, incluindo o job que declaramos anteriormente:
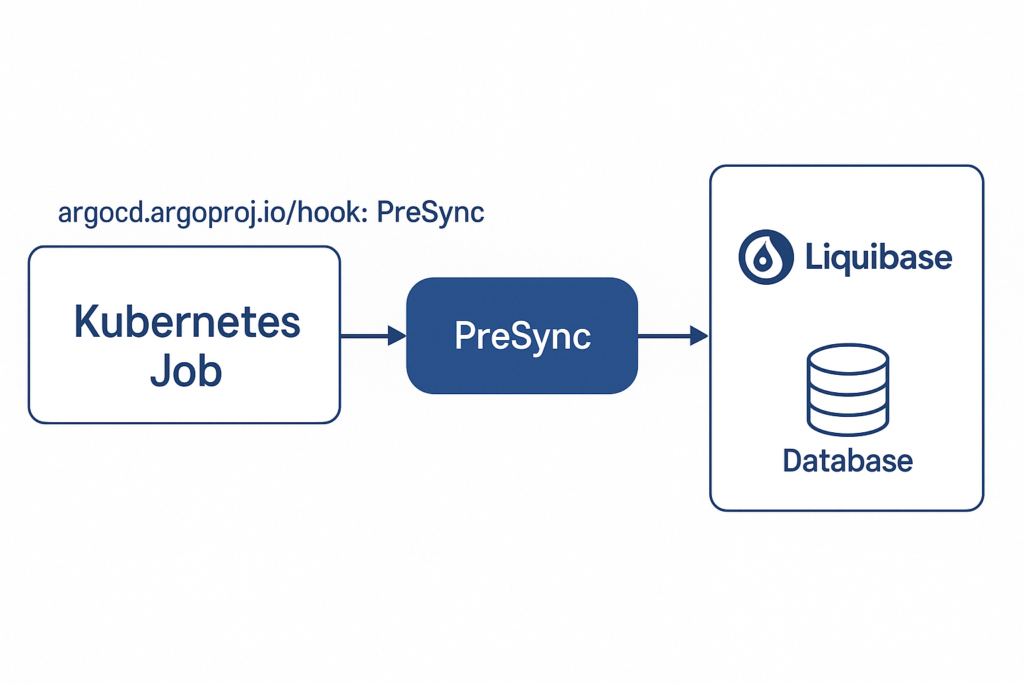
Mas o que isso traz de vantagem? Perceba que se houver uma falha em algum script de migration a nova versão nem é liberada, ou seja, nenhum usuário será afetado pois as etapas posteriores só serão executadas em caso de sucesso no job. Outra vantagem: escalonamento. Uma vez que as migrations já foram executadas no início do processo, se eu precisar escalar minha aplicação (na mesma versão) não é necessário passar por todo o processo de verificação/execução do scripts, trazendo minha nova réplica para o ar mais rapidamente. Muito legal, não?
Rollbacks e demais preocupações
Como nenhuma solução é mágica e essa não é diferente, precisamos tratar alguns aspectos:
– Rollbacks: suponho que tudo tenha ocorrido bem na etapa de PreSync mas por algum motivo a migration executada gerou um efeito colateral no sistema que fez com que a aplicação em si não conseguisse ser inicializada. E agora? Nosso processo de PreSync falhou ou não temos muita escolha? Neste caso poderíamos ter um listener de eventos do próprio Kubernetes, nos interessando por eventos de CrashLoopback (container com erro sendo reiniciado). Esse listener ao receber esse evento poderia disparar um processo de rollback no liquibase, utilizando o mecanismo de tags, para restaurar o estado anterior.
– Tempo de implementação considerável dependendo da maturidade do time: se o time ainda não adotou a estratégia de GitOps pode parecer um tanto desafiador no início, pois novos componentes de infraestrutura e até o mindset precisam ser adequados para o novo fluxo. Porém com base em minha experiência Softwares de nível empresarial (principalmente SaaS) por si só já são complexos e exigem abordagens maduras para lidar com esse tipo de problema.
Considerações finais
A utilização de Resource Hooks do ArgoCD pode ser um grande aliado em nossos processos de rollout, auxiliando na separação de responsabilidades e aumentando as possibilidades de customização. É uma estratégia promissora, possui seus desafios mas vem sendo utilizada com sucesso em ambientes produtivos, justificando o retorno sobre o investimento técnico.
Referências:
[1] https://www.liquibase.com/blog/using-liquibase-in-kubernetes
[2] https://docs.aws.amazon.com/eks/latest/userguide/s3-csi.html

