Em uma arquitetura distribuída é comum enfrentarmos alguns problemas menos comuns ou até mesmo inexistentes em uma arquitetura monolítica. Temos, por exemplo, que lidar com transações distribuídas (sagas), comunicação entre serviços, agregação de queries e tolerância a falhas, para citar alguns.
No que diz respeito à tolerância a falhas, temos que de alguma forma proteger nossos serviços de falhas ou até mesmo indisponibilidade de outros serviços auxiliares. Em uma arquitetura, digamos “naive”, faríamos uma chamada síncrona para um serviço B e esperaríamos uma resposta. Em uma comunicação de rede, entretanto, precisamos levar em consideração vários fatores, latência, falta de resposta, entre outros.
Há algumas ferramentas que nos ajudam a mitigar diversos desses problemas, umas a nível de infraestrutura e outros a nível de aplicação. A nível de infraestrutura temos o Istio, por exemplo, um service Mesh muito poderoso. E a nível de aplicação temos o Resilience4j, que é a ferramenta que vou apresentar neste artigo.
O que é o Resilience4j?
É uma biblioteca para aplicações Java que implementa várias features super interessantes para lidarmos com resiliência e tolerância a falha em nossas aplicações. Ela apresenta uma arquitetura modular, permitindo usar somente o que precisarmos e deixando o artefato da nossa aplicação menor por não trazer coisas desnecessárias. Seus principais componentes são:
-
- Circuit Breaker
- Retry
- Rate Limiter
- Bulkhead
- TimeLimiter
É comum que algumas soluções que já utilizamos em nossas arquiteturas façam overlaping de algumas funcionalidades do Resilience4j. Por exemplo, um API Gateway provavelmente já vai prover a funcionalidade de RateLimiting.
Para que o artigo não fique muito grande, neste post veremos com detalhes somente os módulos de Circuit Breaker e Retry.
Circuit Breaker
Antes de mais nada, Circuit Breaker é um padrão de arquitetura de microserviços. Uma chamada síncrona para um serviço externo deveria utilizar este padrão sempre que possível. Se o serviço externo encontra-se irresponsível ou com um timeout muito elevado não podemos escalar esta indisponibilidade para nossa aplicação. Em termos práticos, as requisições para o nosso serviço vão acumular chegando em um ponto de não ter mais recursos suficientes para atender outras requisições, uma vez que todas as threads estão ocupadas esperando a resposta de um serviço indisponível. Em um ambiente Kubernetes isso significa falha nos probes, levando a um scale-up da aplicação.
Exemplo prático em Java com Spring Boot
O Resilience4j pode ser usado standalone, porém neste tutorial utilizarei o starter do spring-boot que nos fornece todos os módulos da biblioteca. Teremos o seguinte cenário:
- Um serviço rodando em localhost
- O serviço A fará chamadas para um serviço B que está indisponível. Assim teremos a oportunidade de observar o comportamento do padrão Circuit Breaker.
Para simplificar, criaremos um projeto do zero (https://start.spring.io) e vamos utilizar por enquanto somente o spring-boot-starter-web para termos nossa aplicação servida por um servlet container, além da dependência:
<dependency>
<groupId>io.github.resilience4j</groupId>
<artifactId>resilience4j-spring-boot3</artifactId>
<version>${resilience4jVersion}</version>
</dependency>
Esse starter entretanto contradiz o que este artigo afirma no início sobre importar somente as bibliotecas utilizadas. Isso porque o starter tem uma dependência transitiva para o
resilience4j-framework-commonque, este sim, traz todos os módulos do Resilience4j. Not a big deal 🙂
Este vai ser o nosso serviço A, que fará chamadas para um serviço inexistente para simularmos a indisponibilidade. Lembrando que o Resilience4j exige a versão mínima do Java como 17. Com o projeto pronto e importado em sua IDE de preferência, vamos configurar o log da aplicação para que possamos acompanhar os eventos que o Resilience4j emite, assim podemos entender um pouco melhor o que está acontecendo:
logging:
level:
root: info
io.github.resilience4j: debug
Agora vamos criar um controller web para recebermos as requisições para o serviço A, que por vez fará requisições para o serviço B:
@RestController
@Slf4j
public class ServiceAController {
@GetMapping("/serviceA")
@CircuitBreaker(name = "serviceA")
public String callServiceB() {
RestTemplate restTemplate = new RestTemplate();
log.info("Chamando service B");
return restTemplate.getForObject("http://localhost:8081/hello", String.class);
}
}
Temos um web controller convencional, se não fosse pela annotation @CircuitBreaker. Vamos fazer uma requisição para este endpoint para ver o que acontece (lembrando que estamos com o nível de log DEBUG para o Resilience4j):
DEBUG 2109573 --- [nio-8082-exec-1] i.g.r.s.c.c.CircuitBreakerAspect : Created or retrieved circuit breaker 'serviceA' with failure rate '50.0' for method ServiceAController#callServiceB INFO 2109573 --- [nio-8082-exec-1] c.b.t.r.inbounds.ServiceAController : Chamando service B DEBUG 2109573 --- [nio-8082-exec-1] i.g.r.c.i.CircuitBreakerStateMachine : CircuitBreaker 'serviceA' recorded an exception as failure: org.springframework.web.client.ResourceAccessException: I/O error on GET request for "http://localhost:8081/hello": Connection refused at org.springframework.web.client.RestTemplate.createResourceAccessException(RestTemplate.java:915) ~[spring-web-6.1.12.jar:6.1.12]
Exceção esperada porque ainda não temos o service B sendo executado. Mas vamos observar algumas coisas nesse stacktrace:
- Na linha 1 podemos notar que foi criado um circuit breaker com o nome de “serviceA” com uma configuração padrão de failure rate de 50%, ou seja, o circuito será aberto caso 50% das chamadas forem sem sucesso
- Na linha 2 temos o log que inserimos antes da chamada remota
- Na linha 4 em diante temos a stack trace, mas repare que ela foi embrulhada em um objeto chamado
CircuitBreakerStateMachine, e esta é uma ótima hora para voltar um passo e explicar um pouco do que significa essa máquina de estado.
Transição de estado em um circuit breaker
Há 3 estados possíveis:
- aberto
- fechado
- parcialmente aberto
No exemplo acima, o log nos indica que o circuit breaker “A” fará a transição de estado caso 50% das chamadas forem com falha, ou seja, passará do estado “fechado” para “aberto”. Mas o que significa isso? Imagine um circuito eletrônico, se abrirmos o circuito estamos interrompendo o fluxo da energia. O mesmo se aplica aqui, conseguimos abrir o circuito e impedir que novas chamadas sejam feitas para o serviço B, que está indisponível. E o estado “parcialmente aberto”? Após um período, o circuito passa de aberto para parcialmente aberto. Isso significa que apenas algumas requisições serão feitas para o serviço real, afim de checarmos se o serviço já encontra-se disponível. Caso o serviço esteja disponível a chamada será bem sucedida e o circuito será fechado. Caso contrário o circuito voltará a ficar aberto e todo o fluxo se repete.
Fallback
Bem, o cliente da nossa API não se importa com todos esses conceitos de transição de estado e circuit breakers pois ainda estamos recebendo um belo código 500 como resposta:
curl http://localhost:8082/serviceA
{"timestamp":"2024-10-03T23:40:45.494+00:00","status":500,"error":"Internal Server Error","path":"/serviceA"}
Fallbacks caem como uma luva nesses cenários, e é aqui que temos uma vantagem com relação ao Istio Service Mesh. Até a data presente não há um mecanismo que trate esse cenário. Na realidade há até uma issue aberta para o projeto: https://github.com/istio/istio/issues/46240.
Vamos alterar o nosso código para devolver uma resposta alternativa para nosso usuário, como se fosse uma espécie de “consistência eventual”, que inclusive é muito comum em arquiteturas distribuídas:
logging:
level:
root: info
io.github.resilience4j: debug
Agora vamos criar um controller web para recebermos as requisições para o serviço A, que por vez fará requisições para o serviço B:
@RestController
@Slf4j
public class ServiceAController {
@GetMapping("/serviceA")
@CircuitBreaker(name = "serviceA", fallbackMethod = "fallback")
public String callServiceB() {
RestTemplate restTemplate = new RestTemplate();
log.info("Chamando service B");
return restTemplate.getForObject("http://localhost:8081/hello", String.class);
}
public String fallback(Throwable t) {
return "fallback";
}
}
Dessa vez, com o atributo fallbackMethod definimos o código que deve ser executado em caso de exceptions. Basicamente é um try…catch invisível. Há uma regra, porém, que deve ser respeitada ao definir o método de fallback: o último parâmetro precisa ser um objeto do tipo Throwable (ou subtipos). Agora, temos um código 200 na resposta e clientes de nosso serviço/api podem tratar esses retornos “parciais” ao invés de erros 500 genéricos:
curl http://localhost:8082/serviceA fallback
Configurações do circuit breaker
Somente adicionar a annotation @CircuitBreaker não é necessariamente uma solução que a gente busca. O que precisamos é de maneiras de configurar o comportamento do circuito conforme faça sentido para a aplicação que estamos trabalhando. Podemos fazer isso no application.yml:
resilience4j.circuitbreaker:
instances:
serviceA:
minimumNumberOfCalls: 4
failureRateThreshold: 50
waitDurationInOpenState: 10s
permittedNumberOfCallsInHalfOpenState: 3
automaticTransitionFromOpenToHalfOpenEnabled: true
slowCallDurationThreshold: 2000
Vamos analisar com detalhes essas configurações.
- minimumNumberOfCalls: determina o número mínimo de chamadas para a transição de estado acontecer. Neste caso mesmo que 4 chamadas forem efetuadas e todas falhem, o circuito não será aberto.
- failureRateThreshold: configura a taxa de erros para transição de estado. Considerando a configuração acima, a partir da quinta chamada se 50% das execuções falharem o estado do circuito será alterado
- waitDurationInOpenState: determina o máximo de tempo que o circuito ficará aberto antes de fazer a transição de estado para parcialmente aberto
- permittedNumberOfCallsInHalfOpenState: define o número máximo de chamadas permitidas no estado parcialmente aberto. Isso significa que até 3 chamadas serão feitas para o serviço real, para termos a oportunidade de verificar se o mesmo já encontra-se disponível. Na quarta chamada a requisição será negada
- automaticTransitionFromOpenToHalfOpenEnabled: permite que o estado de transição para o estado parcialmente aberto seja feito de forma automática. Por que isso é importante? Não precisamos fazer nenhuma chamada manual para trocar o estado para parcialmente aberto. A desvantagem é que, com este parâmetro ativo, criamos uma thread adicional para monitorar todos os circuitos que estão em estado aberto.
Lembrando que o método de fallback não tem relação nenhuma com as configurações acima. Ele apenas nos dá a possibilidade de retornar um valor alternativo quando o circuito estiver aberto/parcialmente aberto ou chamadas forem recusadas pelo circuito.
Com as configurações acima, podemos fazer um script para testar o comportamento:
for i in {1..7}
do
response=$(curl -s -o /dev/null -w "%{http_code}" http://localhost:8082/serviceA)
echo "Request $i: Response Code = $response"
sleep 2
done
Em um intervalo de 2 segundos fiz 7 chamadas. Vamos analisar os logs a seguir.
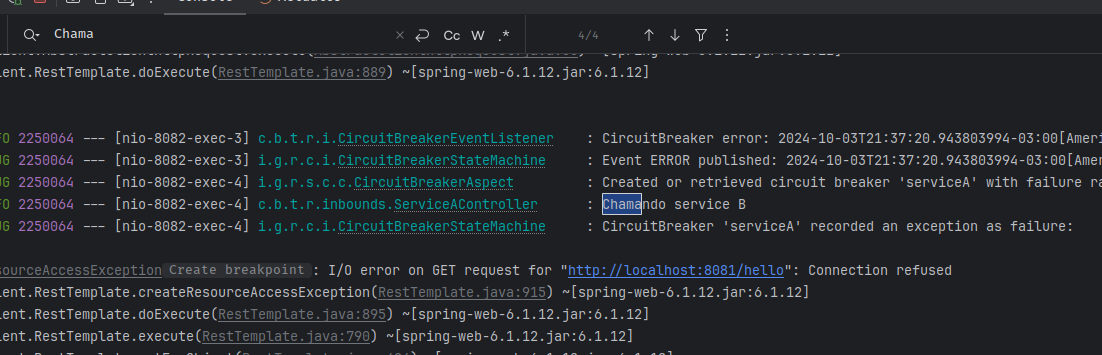
Perceba que no log só encontramos até a quarta request para o serviço. Isso aconteceu porque definimos como 4 o parâmetro minimumNumberOfCalls. A partir da quarta request os indicadores do circuit breaker começaram a ser registrados e chamadas posteriores foram rejeitadas. Vamos analisar outros detalhes do log.
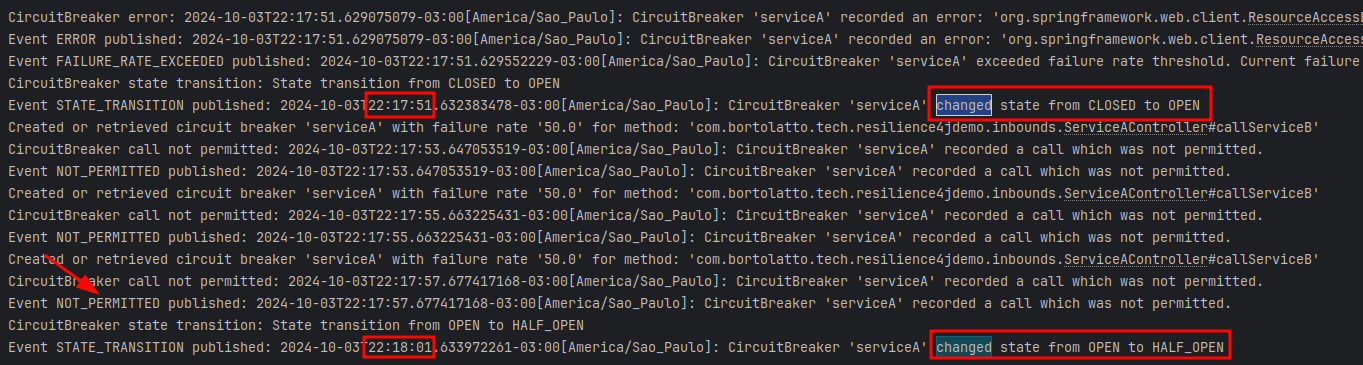
Primeiro, podemos ver que no período de 10 segundos o estado do circuito foi alterado de fechado para aberto e de aberto para parcialmente aberto. Esses 10 segundos é justamente o tempo que definimos no parâmetro waitDurationInOpenState. Podemos observar também que durante o período em que o circuito esteve aberto novas requisições foram rejeitadas automaticamente. Isso é muito vantajoso, pois não há sentido em insistir em requisições para um serviço indisponível. Devemos economizar os recursos de nossa aplicação para atender outros tipos de requisições saudáveis.
EventListeners
Alterar o nível de log vai nos dar parcialmente o que precisamos. Além do log tradicional o Resilience4j nos dá a oportunidade para tomarmos ações em determinados acontecimentos no circuito. Por exemplo, se estivermos interessados em eventos de transição de estados, podemos registrar um listener para o evento CircuitBreakerOnStateTransitionEvent. Vamos criar uma classe para escutar os eventos:
@Component
@Slf4j
@RequiredArgsConstructor
public class CircuitBreakerEventListener {
private final CircuitBreakerRegistry circuitBreakerRegistry;
@PostConstruct
public void setUp() {
circuitBreakerRegistry.getAllCircuitBreakers().forEach(this::registerEventListeners);
}
public void handleSuccessEvent(CircuitBreakerOnSuccessEvent event) {
log.info("CircuitBreaker success: {}", event);
}
public void handleErrorEvent(CircuitBreakerOnErrorEvent event) {
log.info("CircuitBreaker error: {}", event);
}
public void handleStateTransitionEvent(CircuitBreakerOnStateTransitionEvent event) {
log.info("CircuitBreaker state transition: {}", event.getStateTransition());
}
public void handleResetEvent(CircuitBreakerOnResetEvent event) {
log.info("CircuitBreaker reset: {}", event);
}
public void handleIgnoredErrorEvent(CircuitBreakerOnIgnoredErrorEvent event) {
log.info("CircuitBreaker ignored error: {}", event);
}
public void handleCallNotPermittedEvent(CircuitBreakerOnCallNotPermittedEvent event) {
log.info("CircuitBreaker call not permitted: {}", event);
}
private void registerEventListeners(CircuitBreaker cb) {
cb.getEventPublisher()
.onSuccess(this::handleSuccessEvent)
.onError(this::handleErrorEvent)
.onStateTransition(this::handleStateTransitionEvent)
.onReset(this::handleResetEvent)
.onIgnoredError(this::handleIgnoredErrorEvent)
.onCallNotPermitted(this::handleCallNotPermittedEvent);
}
Nesta classe estamos registrando listeners para todos os tipos de evento. Perceba que temos um mecanismo para que isso funcione. Veja por exemplo a classe CircuitBreakerRegistry que é injetada pelo Spring. Nela temos acesso de forma global à todos os circuit breakers configurados.
Retries
What a journey it has been! Na última seção deste artigo, apresento a funcionalidade de retries. O Istio Service Mesh também consegue nos entregar a mesma coisa, vale a pena dar uma conferida. No Resilience4j a configuração é trivial e bem intuitiva. Porém há uma pegadinha… sempre tem. Primeiro, vamos tentar utilizar o retry de forma isolada, substituindo a annotation @CircuitBreaker por @Retry, lembrando que o retry também permite retorno de fallback então vamos manter o método.
@GetMapping("/serviceA")
@Retry(name = "serviceA", fallbackMethod = "fallback")
public String callServiceB() {
RestTemplate restTemplate = new RestTemplate();
log.info("Chamando service B");
return restTemplate.getForObject("http://localhost:8081/error", String.class);
}
Agora vamos adicionar a configuração de retry no application.yml:
resilience4j.retry:
instances:
serviceA:
maxAttempts: 6
waitDuration: 3s
Agora, o teste com o comando cURL, adicionando a flag -v (verbose) para observamos o payload e o status code da resposta:
curl http://localhost:8082/serviceA -v * Trying 127.0.0.1:8082... * Connected to localhost (127.0.0.1) port 8082 (#0) > GET /serviceA HTTP/1.1 > Host: localhost:8082 > User-Agent: curl/7.81.0 > Accept: */* >
Depois de alguns segundos, podemos observar a resposta:
* Mark bundle as not supporting multiuse < HTTP/1.1 200 < Content-Type: text/plain;charset=UTF-8 < Content-Length: 8 < Date: Fri, 04 Oct 2024 02:34:22 GMT < * Connection #0 to host localhost left intact fallback
Muito legal, não? Recebemos um status code 200, com um payload razoável que os clientes dessa API poderão tratar. Agora, vamos observar o log da aplicação:
2024-10-03T23:34:07.303-03:00 DEBUG 2489705 --- [nio-8082-exec-3] i.g.r.s.retry.configure.RetryAspect : Created or retrieved retry 'serviceA' with max attempts rate '6' for method: 'com.bortolatto.tech.resilience4jdemo.inbounds.ServiceAController#callServiceB' 2024-10-03T23:34:07.304-03:00 INFO 2489705 --- [nio-8082-exec-3] c.b.t.r.inbounds.ServiceAController : Chamando service B 2024-10-03T23:34:10.305-03:00 INFO 2489705 --- [nio-8082-exec-3] c.b.t.r.inbounds.ServiceAController : Chamando service B 2024-10-03T23:34:13.309-03:00 INFO 2489705 --- [nio-8082-exec-3] c.b.t.r.inbounds.ServiceAController : Chamando service B 2024-10-03T23:34:16.312-03:00 INFO 2489705 --- [nio-8082-exec-3] c.b.t.r.inbounds.ServiceAController : Chamando service B 2024-10-03T23:34:19.314-03:00 INFO 2489705 --- [nio-8082-exec-3] c.b.t.r.inbounds.ServiceAController : Chamando service B 2024-10-03T23:34:22.317-03:00 INFO 2489705 --- [nio-8082-exec-3] c.b.t.r.inbounds.ServiceAController : Chamando service B
Veja que no intervalo de 3 segundos as chamadas são efetuadas! Isso mostra que nossa configuração de fato fez o efeito desejado, com as 6 tentativas corretamente sendo efetuadas.
There is always a catch…
Como dito no início do artigo, o Resilience4j é um framework modular. É possível decorar o comportamento de nosso circuit breaker, adicionando camadas de configuração. Vamos voltar ao nosso exemplo, mas dessa vez vamos deixar as duas annotations configuradas: @CircuitBreaker e @Retry com suas respectivas configurações de fallback:
@GetMapping("/serviceA")
@CircuitBreaker(name = "serviceA")
@Retry(name = "serviceA", fallbackMethod = "fallback")
public String callServiceB() {
RestTemplate restTemplate = new RestTemplate();
log.info("Chamando service B");
return restTemplate.getForObject("http://localhost:8081/error", String.class);
}
Ao efetuarmos o mesmo teste com o cURL anteriormente, vemos algo errado:
curl http://localhost:8082/serviceA -v * Trying 127.0.0.1:8082... * Connected to localhost (127.0.0.1) port 8082 (#0) > GET /serviceA HTTP/1.1 > Host: localhost:8082 > User-Agent: curl/7.81.0 > Accept: */* > * Mark bundle as not supporting multiuse < HTTP/1.1 200 < Content-Type: text/plain;charset=UTF-8 < Content-Length: 8 < Date: Fri, 04 Oct 2024 02:51:30 GMT < * Connection #0 to host localhost left intact fallback
Imediatamente após a requisição já recebemos o código 200 e o payload de fallback. Se olharmos no log da aplicação, temos um cenário ainda mais estranho:

Onde foram parar as 6 chamadas que configuramos no retry?
AspectOrder
A integração entre o Spring e o Resilience4j se dá através de aspectos. Se você não sabe o que é isso, basicamente é uma forma de injetar dinamicamente comportamentos no seu código, de forma transparente e em runtime. O SpringFramework faz um uso massivo de aspectos, vale a pena explorar um pouco mais esse tema.
Enfim, voltando: com o Resilience4j não é diferente. Acontece que os aspectos tem uma ordem específica de execução, sendo:
Retry ( CircuitBreaker ( RateLimiter ( TimeLimiter ( Bulkhead ( Function ) ) ) ) )
Ou seja, o Retry está por último na cadeia. Como nosso CircuitBreaker é executado antes e temos um fallback para ele, o Retry nem é executado. Para que tenhamos o comportamento anterior, basta retirar a configuração de fallback do @CircuitBreaker! E o mais interessante é que, após fazer isso, ao invés de vermos 6 chamadas sendo feitas para o serviço B, vemos somente 4… você sabe o por que? Bem, se você chegou até aqui parabéns, já deve saber a resposta 🙂
Há muito mais o que explorar
Embora o artigo tenha ficado ligeiramente longo há algumas coisas que deixei de fora, caso contrário iria ser uma leitura mais chata ainda. Vale a pena dar uma brincada com outros módulos do Resilience4j, como Bulkhead por exemplo.
O Resilience4j é uma biblioteca fantástica! Até a próxima!